Survey Data
Another common data type that you might want to use NVivo to analyze is survey data. NVivo can import survey data in directly from SurveyMonkey and Qualtrics, so if you use those tools, just select those options from the Import Ribbon. However, you may have your survey data just stored in a spreadsheet, where each row is a survey respondent’s answers and each column is a question. We can also import this type of data into NVivo.
Note: This activity assumes you are familiar with case classifications and cases in NVivo. If case classifications and cases in NVivo is new to you, you can learn more in our Introduction to NVivo 15 tutorial!
To start, let’s download a small sample of survey data called the Millennial Sentiment Interview Transcript Dataset. This data set is hosted on Kaggle, which is an public data platform. To download this data you’ll first have to register for a free account (or sign in if you already have one). Click Register at the top right of the website.
After you’ve signed in, click the little download arrow next to the file name and save it somewhere you can find it, such as the Desktop.
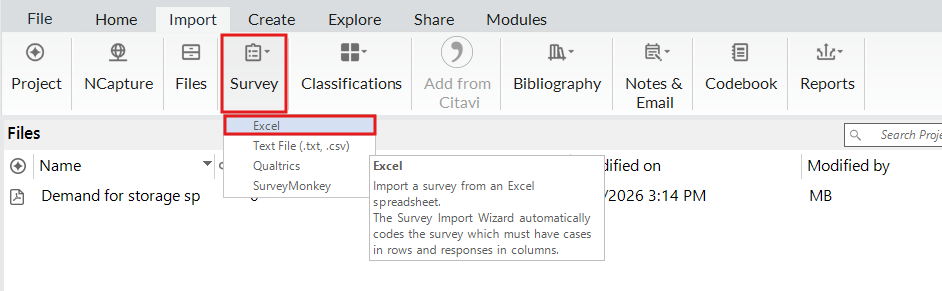
Go to NVivo. Create a new project file or open up an existing project file that you want to import this into. From the top menu, under Import, select Survey > Excel.
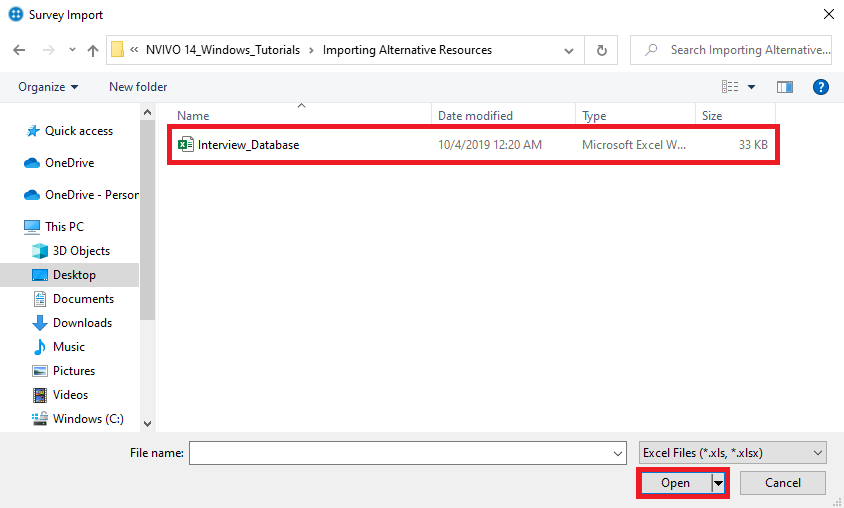
Browse to the folder where the Millennial Sentiment Interview Transcript Dataset (file Interview_Database.xlsx) was saved. Select the file, and then click on Open.
NVivo’s Survey Import Wizard will open up to help you import your data. For each row, it will create a case for the survey respondent. For each closed-ended question that it detects, it will capture that information about the survey respondent as case attributes. Then it will import each open-ended question as spreadsheet content that can be coded, and automatically code each question’s response with a new code for that question. Let’s go through the wizard together to see this in action. Click on Next.
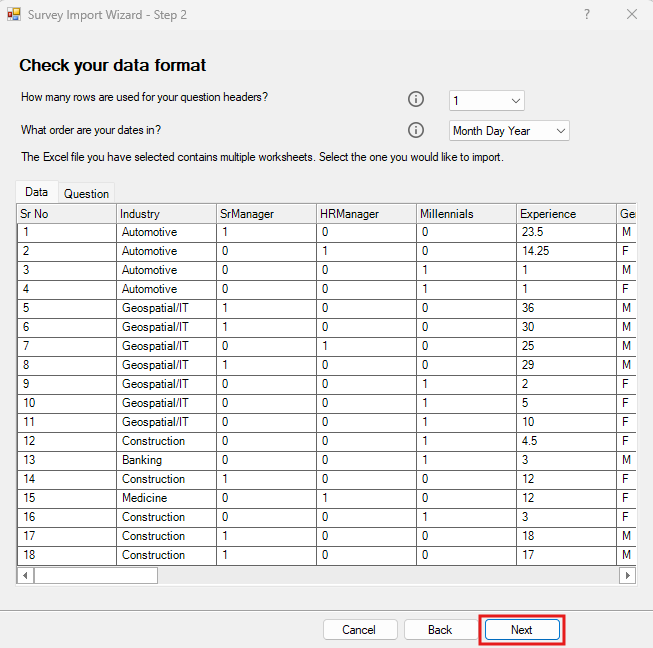
First it checks the data format. Our first row is our column headers, so we can keep the default. We don’t have any dates in our survey, so again we can keep the default, but if you are working with dates, then take a look at this option. It will also present you with a preview of the data. Click on Next.
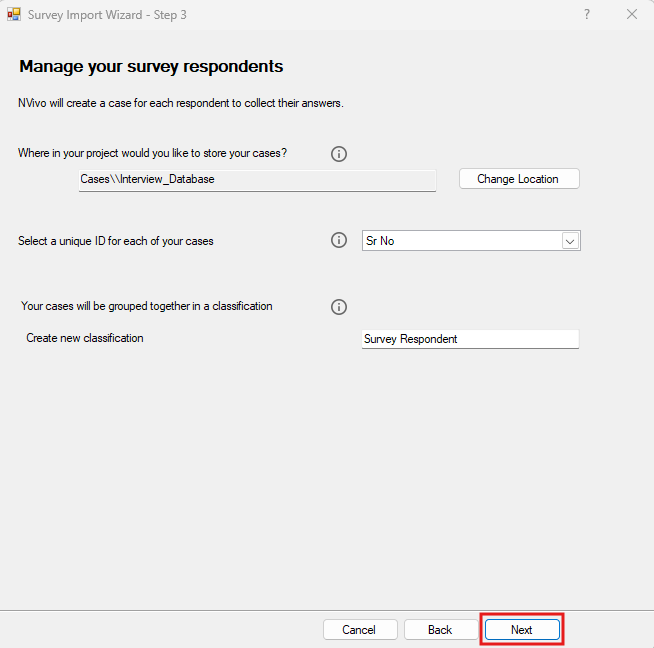
The next screen asks for information about creating cases and case classifications for our survey respondents (i.e., rows) in our dataset. In this case, we can keep all the defaults, as it will create a new case classification called Survey Respondent, and it will use the column Sr No as the unique ID for each case, which makes sense. Click on Next.
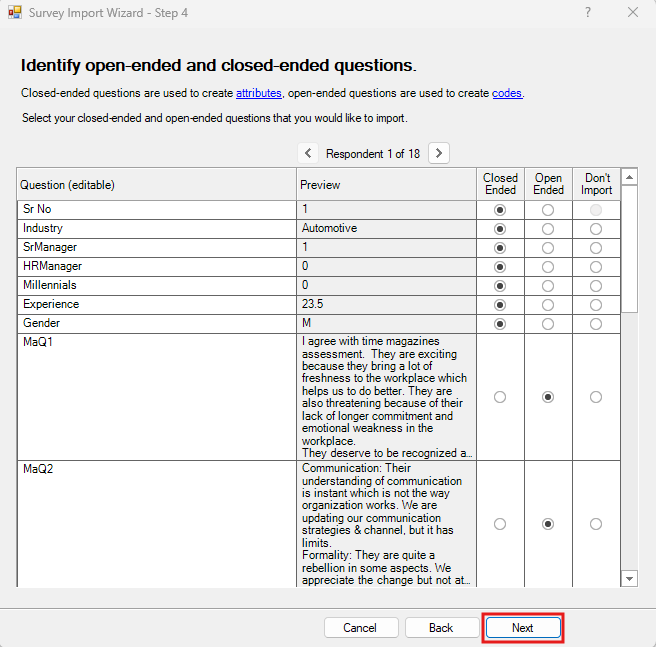
The next screen automatically detects which questions are closed-ended and will be used for attributes in this case classification. You can correct NVivo if there are any mistakes. You can also choose any columns that you don’t want to import. In our case, it looks good, so click on Next.
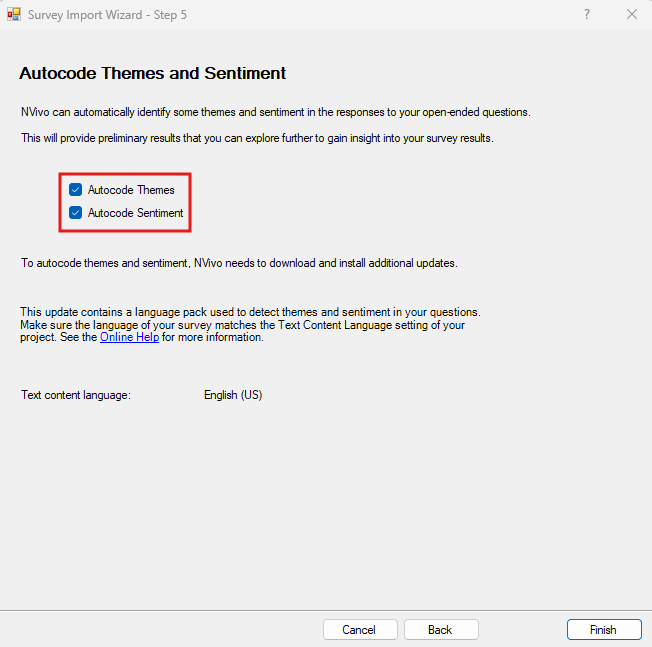
The next screen provides you an option to autocode responses by sentiment (i.e., positive or negative). Sentiment can be useful, especially if you have a huge amount of survey responses and won’t be manually coding all the answers, but want to get a sense of the content. For example, a survey question might be – did you like a particular product, and then NVivo can code for sentiment to see if generally people liked it or didn’t like it.
Note: In order to use this autocode sentiment feature, you need to sign up for a MyLumivero Portal account. Launch the MyLumivero Portal, select Sign up now, and follow the instructions to create an account. You then will need to log into the portal with this account first, before selecting autocode sentiment in the survey import wizard. NVivo asks you to log in on the welcome screen when you first start up the program. Keep in mind, though, that the University of Toronto has not reviewed these accounts for privacy concerns. You sign up for an account at your own risk.
In our case, let’s uncheck this option for now. Then click Finish to complete importing in our data.
You will see a progress screen. When it is finished, click on Close.
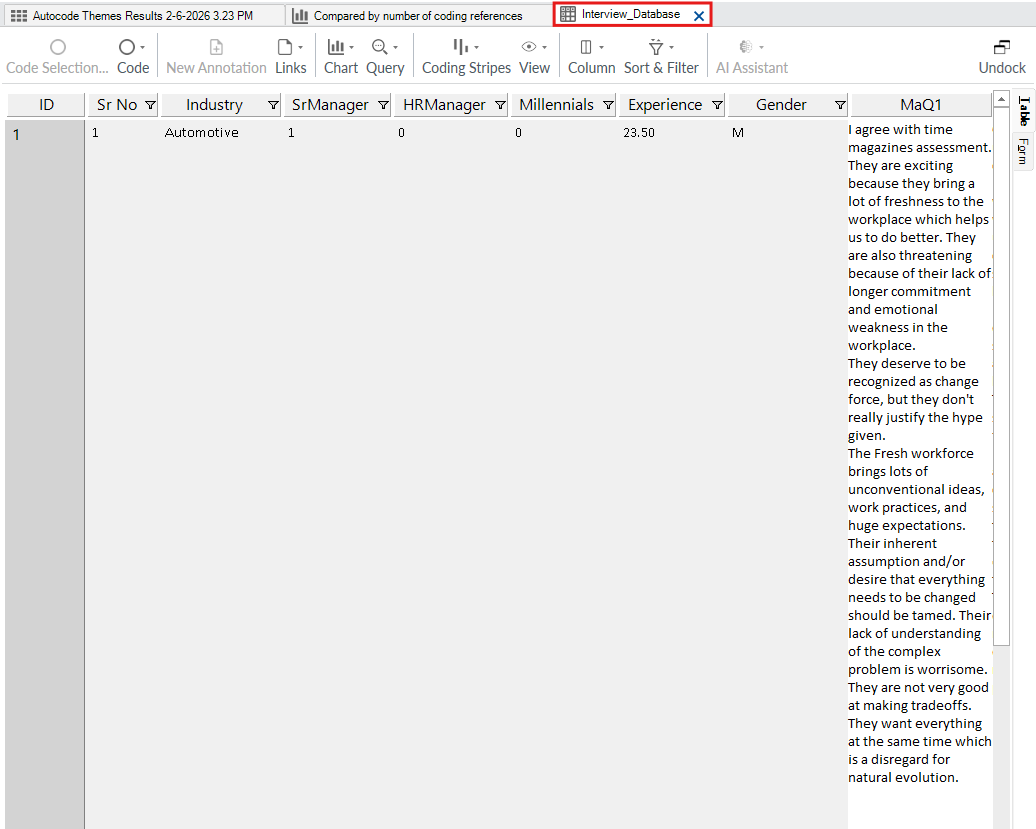
NVivo will open up a tab with your survey data in spreadsheet format. This is where you can read through the responses and code the data.
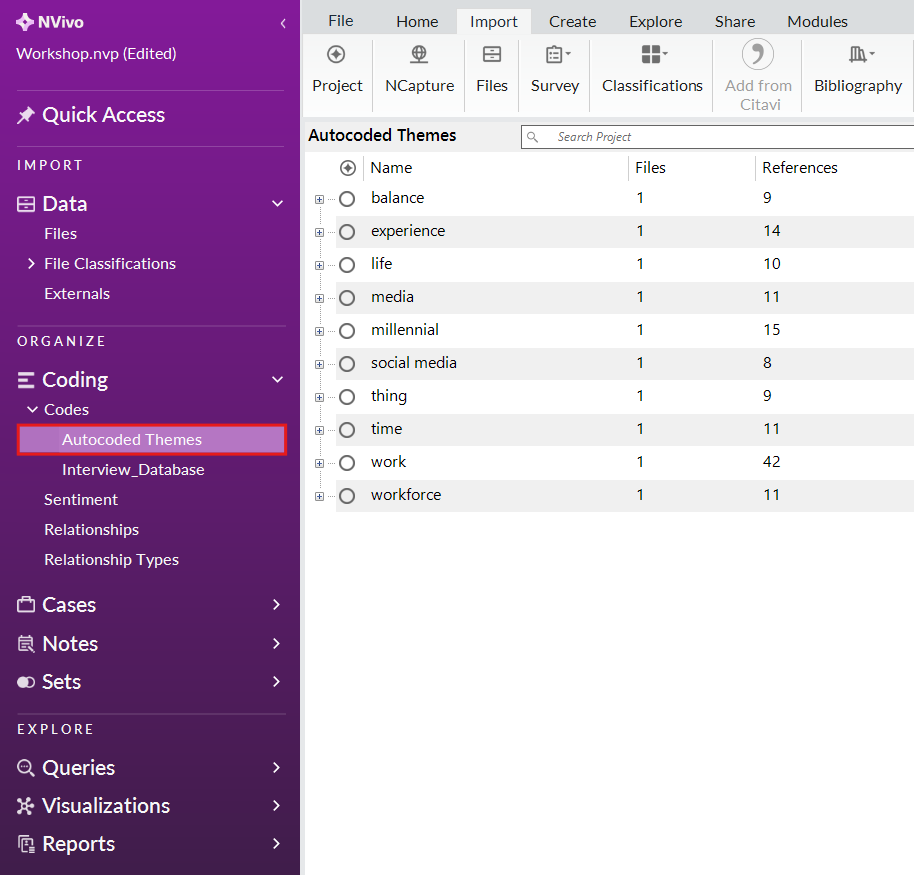
Using the left menu, under Coding, expand Codes, to explore the autogenerated codes. Click on the Interview_Database folder to explore the codes that were autogenerated for each question.
Using the left menu, under Cases, expand Cases, to explore the autogenerated cases. Click on the Interview_Database folder to explore the cases that were autogenerated for each survey participant with their attributes pulled from the closed-ended questions.
Now your survey data has been imported and organized, ready for analysis!
Technique: Qualitative Data Analysis | Tool: NVivo